When AI Writes Your Emails: A Study on Trust, Transparency, and Human Oversight
Here's the thing about AI and email that keeps me up at night. Everyone's using ChatGPT, Claude, Gemini, and every other AI writing tool to draft their messages. It's happening everywhere. Professors, administrators, customer service reps, your coworkers. I think it's becoming the norm. And I think sometimes, when people find out that an email they received was AI generated, something weird happens. Sometimes, trust drops.
I'm researching this exact problem at UTRGV, and what started as a simple question about AI transparency has turned into something way more complicated and way more interesting than I expected.
The Impossible Choice
The problem organizations face right now is challenging. You can use AI writing tools and not tell anyone, which works great until someone finds out and then you look dishonest. Or you can be transparent about using AI and watch your credibility tank, even when the emails are well written and appropriate.
Research has already documented this disclosure penalty pretty thoroughly. Jakesch and colleagues showed back in 2019 that when people are told a profile was written with AI assistance, they perceive the author as less trustworthy. The content doesn't change. The only thing that changes is the label saying AI was involved. That's enough to shift trust downward. Liu and team extended this into email communication in 2022, testing everything from transactional thank you emails to highly emotional condolence messages. They found that trust in email writers decreased when AI involvement was disclosed, with particularly severe penalties in high emotion contexts where people value personal attention and emotional labor.
What really struck me about Liu's work was the interviews. People explained that knowing about AI involvement fundamentally changed their interpretation of sender effort, intention, and care, even when they acknowledged the messages were well written. They cared deeply about the process behind message creation, not just the final text quality. And here's the kicker. Even the warmest, most personalized AI disclosed messages still received lower trust ratings than comparable human written messages. Interpersonal warmth mitigated the penalty but didn't eliminate it.
So we're stuck. AI tools are incredibly useful. They save time, improve consistency, help people who struggle with writing. But the moment you're honest about using them, you pay a trust cost. That's the problem I wanted to solve.
The Human in the Loop Solution
My approach centers on something called human in the loop, or HITL for short. The idea is simple but potentially powerful. Instead of having AI write entire emails autonomously or having humans write everything from scratch, what if the AI drafts and the human edits, approves, and takes responsibility? It's co-authorship. The AI provides the efficiency and consistency, the human provides the judgment, accountability, and care.
This isn't just a nice theoretical idea. Recent research emphasizes that integrating human oversight strategies like HITL enhances transparency and accountability while ensuring that AI driven decisions remain aligned with ethical, legal, and societal standards. Wu and colleagues did this comprehensive survey in 2022 showing that human in the loop approaches generally improve trust in AI assisted decision making across all kinds of domains. The catch is that most of those findings come from decision support contexts, not communication scenarios. Nobody had actually tested whether HITL could restore trust in email specifically.
The theoretical argument for why HITL should work comes from Mayer, Davis, and Schoorman's 1995 integrative model of organizational trust. They define trust as the willingness to be vulnerable to the actions of another party based on the expectation that the other will perform appropriately, even when you can't monitor or control them directly. When you trust someone who sends you an email, you're accepting vulnerability to potential insincerity or lack of care because you believe they'll act appropriately despite your inability to verify their true intentions or effort.
Mayer and colleagues identified three distinct dimensions of trustworthiness. Ability refers to the skills and competencies that enable someone to have influence in a specific domain. In email, this is the sender's perceived competence in crafting appropriate, well written, contextually suitable messages. Integrity involves adherence to principles that you find acceptable, like honesty, promise fulfillment, and fairness. In communication, this shows up as questions about whether the sender is being honest about their effort investment and whether they're representing themselves authentically. Benevolence represents the extent to which someone wants to do good for you, aside from selfish motives. In emails, this reflects whether you believe the sender cares enough about you and your relationship to invest personal time and attention.
Here's why the disclosure penalty is so hard to overcome. When AI involvement is disclosed, recipients may question all three dimensions simultaneously. If they were competent, why do they need AI assistance? Did they really invest personal effort, or did they just approve an AI draft? Does the sender care enough about me to write this themselves? An intervention that addresses only one dimension while leaving others unaddressed would probably show limited effectiveness.
Human in the loop workflows theoretically address all three dimensions at once. Explicit human review and approval signals ability through demonstrated competence in evaluating output. It signals integrity through taking responsibility and investing genuine effort. And it signals benevolence through caring enough to ensure the message appropriately reflects intentions and relationship context. At least, that's the theory. I wanted to test whether it actually works.
Understanding Different Types of Trust
To design this study properly, I had to get deep into the trust literature. Hoff and Bashir's 2015 systematic integration of trust in automation research was crucial because they distinguish between dispositional trust and situational trust. This distinction explains why different people can respond totally differently to identical disclosure conditions.
Dispositional trust encompasses the stable individual differences that people bring to any trust situation before they have specific experience with a particular trustee or system. This includes propensity to trust, which reflects a general tendency to believe others are benevolent, reliable, and honest. People high in propensity to trust approach new situations with an initial presumption of trustworthiness. They interpret ambiguous signals generously and give others the benefit of the doubt. Those low in propensity to trust maintain skepticism, interpreting the same signals more negatively and requiring stronger evidence before extending trust.
In the context of AI mediated communication, dispositional propensity to trust shapes how recipients initially respond when they learn a message involved AI assistance. High propensity individuals may assume that AI assistance was used appropriately and that the sender still invested adequate personal attention. Low propensity individuals may immediately suspect that AI use indicates minimal sender effort or care. These dispositional characteristics remain relatively stable across situations and represent the baseline from which situational trust judgments develop.
Situational trust, in contrast, represents trust judgments formed in response to specific interactions with a particular agent in a particular context. Unlike dispositional trust which people carry across situations, situational trust emerges from and responds to the immediate context. This includes the specific task at hand, the perceived stakes of the interaction, the characteristics of the message being evaluated, disclosed information about how the message was created, and environmental factors that influence judgment. Situational trust can change rapidly based on new information. The same person might show high trust when reading a human written thank you email and low trust when reading an AI generated condolence message because the appropriateness of AI involvement and the stakes of authentic human connection differ dramatically.
The critical insight is that dispositional and situational trust interact dynamically. Dispositional propensity to trust sets the initial baseline and creates individual differences in how strongly people react to situational factors like authorship disclosure. People with high dispositional trust may show smaller disclosure penalties because they start with favorable assumptions and interpret AI involvement charitably. Those with low dispositional trust may show larger penalties because disclosure triggers existing skepticism and confirms suspicions that automation replaces authentic human connection.
This interaction means that interventions like human in the loop workflows may work differently for different groups. Individuals who are dispositionally skeptical may require particularly strong signals of human involvement and oversight to overcome their baseline reluctance to trust. Those who are dispositionally trusting may extend trust more readily even with minimal evidence of human oversight. I needed to measure both types of trust to separate system effects from prior attitudes and see who benefits most from HITL.
Designing the Experiment
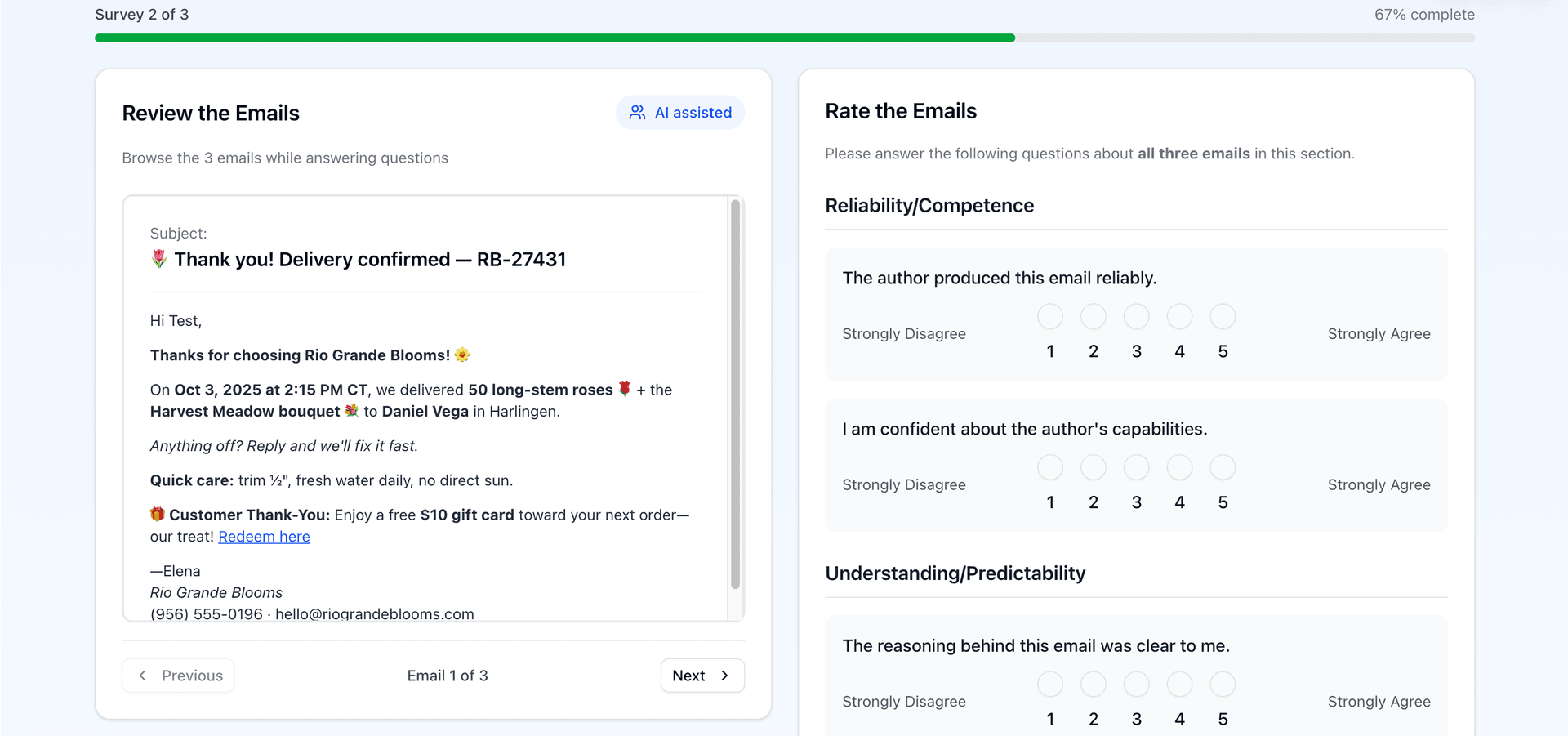
My research design tests three authorship conditions across multiple email contexts. The three conditions are human only, where a person writes the entire email from scratch with no AI assistance. Human in the loop, where AI drafts the message and a human reviews, edits, approves, and takes responsibility. And AI only, where AI generates the message autonomously with no human oversight. Crucially, I'm disclosing the authorship condition for every email. There's no deception. Participants always know which condition they're reading.
I'm using a within subjects design, meaning every participant evaluates emails under all three conditions. This lets me isolate the effect of authorship by comparing the same person's reactions across different conditions. It's way more statistically powerful than between subjects designs because you control for all the individual differences by using each person as their own baseline.
For email contexts, I'm testing three scenarios that vary in stakes and interpersonal emphasis. A thank you email represents a low stakes transactional communication. An event invitation sits in the middle with moderate stakes and some interpersonal warmth. A job offer email represents high stakes communication where recipients really care about authenticity and personal attention. Testing across these contexts lets me see whether HITL effectiveness depends on the type of email or whether it works broadly.
Before participants read any emails, I collect brief measures of their dispositional characteristics using items from Körber's Trust in Automation scale. Körber developed this validated instrument in 2018 through careful theoretical integration of existing trust frameworks, including explicit incorporation of Mayer's ability integrity benevolence model and Hoff and Bashir's dispositional situational distinction. For dispositional trust, I'm measuring propensity to trust with items like "I rather trust AI based systems than mistrust them" and "One should be careful with unfamiliar automated systems," which is reverse coded. I'm also measuring familiarity with AI through items like "I already know systems that help people write emails" and "I have used AI tools to help compose or edit emails." These pre task measures give me each participant's baseline.
After reading each email, participants respond to situational trust items adapted from the TiA scale. These capture reliability and competence through items like "The author produced this email reliably" and "The author seems capable of writing clear and well structured emails, even for complex topics." They measure understandability and predictability with "The reasoning behind this email was clear to me" and reverse coded items like "It is difficult to predict how this author would write in a similar situation." They assess intention of developers and authors through "The people who design or use the tools to produce this email have the recipient's interests in mind." And they measure overall trust directly with "I trust the authoring process behind this email" and "I can rely on the authoring process behind this email."
All items use five point Likert scales from strongly disagree to strongly agree. I reverse code the negative items and then compute mean scores for each subscale. This gives me multidimensional trust profiles for each email rather than just a single trust number. Some emails might score high on reliability but low on benevolence. Others might show the opposite pattern. The granularity matters because it helps me understand exactly how HITL affects trust.
What I'm Testing
My first research question asks whether human in the loop co-authorship produces higher trust than AI only and achieves trust levels comparable to human only across common email contexts. This operationalizes the core theoretical prediction that HITL should bridge the gap between automation efficiency and human level trust.
I have two specific hypotheses for this question. Hypothesis one predicts that HITL will produce higher overall trust scores than AI only. This tests whether the intervention successfully mitigates the trust damage that occurs when recipients learn messages were created through pure automation. I'm comparing HITL against AI only across all participants and all email contexts. If this hypothesis is supported, I'll have evidence that adding human oversight makes a meaningful difference.
Hypothesis two predicts that HITL will produce trust scores within a small predetermined equivalence margin of human only authorship. This goes beyond asking whether HITL improves on AI only to test whether HITL actually achieves the ultimate goal of restoring trust to practically equivalent levels as fully human composition. I'm not trying to show that HITL is statistically significantly different from human only. Instead, I'm using non inferiority testing with a predetermined equivalence margin. The practical goal is to show that HITL remains close enough to human only that the difference doesn't matter for real world communication effectiveness.
If both hypotheses are supported, I'll have demonstrated that HITL occupies an optimal middle ground, substantially outperforming pure automation while remaining functionally equivalent to fully human authorship. This would provide organizations with validated guidance for implementing AI writing tools transparently without incurring meaningful credibility costs.
My second research question asks whether HITL effectiveness depends on recipient characteristics such as propensity to trust and familiarity with AI. Rather than assuming HITL will work equally well for everyone, this treats individual differences as potential moderators of the authorship trust relationship.
Hypothesis three predicts that the effect of authorship condition on overall trust will be moderated by recipients' propensity to trust and familiarity with AI. In statistical terms, I expect significant interaction effects between authorship condition and propensity, and between authorship condition and familiarity. I'm particularly interested in how these moderators change the trust difference between HITL and AI only conditions.
The reason I frame this as moderation rather than making a specific directional prediction is that theory supports plausible arguments in both directions. On one hand, skeptical individuals with low propensity to trust and low AI familiarity might show the largest increase in trust when moving from AI only to HITL because explicit human involvement addresses their core concerns about accountability and care. On the other hand, more AI familiar or generally trusting individuals might show stronger differentiation between AI only and HITL because they better understand what human oversight entails and value it accordingly. The current literature doesn't provide a clear answer, so I'm treating it as an open empirical question.
Building the Survey
Right now, I'm in the process of building out the actual survey and preparing a website to host it. We'll be recruiting participants through SONA, which is this automated participant pool management system that helps researchers set up studies, recruit participants, and manage course credits. Students enrolled in general psychology will get course credit for completing the survey, and students in other psychology courses can get extra credit at their instructor's discretion. The whole thing should take about 45 minutes to complete on Qualtrics.
We're designing it carefully to avoid coercion. SONA provides alternative research activities in the form of research papers for students who don't want to take surveys. At the beginning, participants will see informed consent explaining the study and explicitly notifying them about their right to withdraw without penalty at any point. We're planning to collect data between fall 2025 and spring 2026, pending IRB approval.
The email scenarios themselves are one of the trickiest parts. I need to write emails that are realistic, well matched across conditions, and varied enough to test generalizability. For each of the three contexts, thank you, event invitation, and job offer, I'm creating three versions that differ only in disclosed authorship. The human only version says written by a person. The HITL version says drafted by AI and reviewed and approved by a person. The AI only version says generated by AI. The actual content stays as similar as possible because I want to isolate the effect of authorship disclosure rather than confounding it with content differences.
Writing these emails has been an iterative process. I draft something, test it on a few people, get feedback, revise, repeat. The goal is to make them sound natural and appropriate for the context while keeping them standardized enough that I can legitimately attribute differences in trust to authorship rather than to quirks in how I phrased a particular sentence.
The Analytics Plan
Once I have the data, the analysis will use mixed effects models to account for the within subjects structure. Each participant contributes multiple observations, one for each email they evaluate, so standard regression techniques would violate independence assumptions. Mixed effects models handle this by including random intercepts for participants, which allows baseline trust to vary across individuals while estimating fixed effects for authorship condition, email context, and their interactions.
For hypothesis one, I'll compare HITL mean trust scores against AI only mean trust scores using planned contrasts within the mixed effects framework. A significant positive difference supports the hypothesis that HITL restores trust relative to pure automation.
For hypothesis two, I'll use equivalence testing with a predetermined margin. Instead of asking whether HITL is statistically different from human only, I'll ask whether the difference between them is small enough to be practically negligible. I'll set the equivalence margin based on the smallest effect size I consider meaningful, probably around a quarter point on the five point scale. If the confidence interval for the HITL versus human only difference falls entirely within that margin, I can claim equivalence.
For hypothesis three, I'll add interaction terms to the mixed effects model testing whether the authorship effect on trust changes as a function of propensity to trust and AI familiarity. I'll treat these as continuous moderators and examine the authorship by propensity interaction and the authorship by familiarity interaction. Significant interactions mean that the HITL advantage varies systematically across people with different baseline characteristics. I can then probe the interactions to see exactly how the effect changes. For instance, does HITL provide the biggest trust boost for skeptical low propensity individuals, or does it work better for trusting high familiarity individuals?
I'll also report descriptive statistics for each subscale separately. While the hypotheses focus on overall trust, the multidimensional structure means I can see whether HITL affects reliability, understandability, and intention differently. Maybe HITL fully restores reliability perceptions but still lags on benevolence. That kind of granularity would be super valuable for understanding exactly what human oversight signals to recipients.
Why This Matters
The societal benefits of this research stem from its potential to resolve the fundamental tension between deceptive opacity and credibility damaging transparency. If HITL workflows can maintain transparency without incurring trust costs, that provides a viable model for responsible AI adoption that preserves both ethical transparency and practical credibility.
For individual users, validated HITL practices would provide a reliable framework for using AI writing tools without damaging professional relationships. This is particularly valuable for people who struggle with writing due to language barriers or learning differences, allowing them to benefit from AI assistance without social penalty. It also benefits message recipients by promoting honest communication practices, allowing them to develop appropriate trust calibration. When you know how a message was created, you can make informed decisions about how much weight to give it.
For organizations, the study provides actionable guidance on AI communication policies. They could implement clear policies about AI use, human oversight requirements, and disclosure practices based on empirical evidence rather than guesswork. Right now, most organizations are winging it. They're making decisions about AI communication without data. This research would give them validated practices they can actually implement.
For computer science and human computer interaction specifically, this advances understanding of how design choices affect user trust and acceptance. The research provides empirical evidence about whether human in the loop architectures deliver their theoretically promised benefits in real communication contexts. It contributes methodologically by demonstrating how to rigorously evaluate trust in AI mediated communication systems using validated multidimensional trust measurement scales rather than focusing solely on text quality metrics.
By systematically comparing human only, HITL, and AI only authorship, the study provides evidence about where on the collaboration spectrum different trust outcomes emerge, advancing theoretical understanding of optimal human AI division of labor. It also examines whether one promising pattern for ethical AI use actually works in practice, contributing to computer science's growing engagement with ethical AI development.
The Reality Check
I'll be honest about the limitations. Our sample is drawn from college students, a population with above average familiarity and comfort with AI tools. This may inflate trust in disclosed AI use and the effectiveness of HITL relative to non student or low AI exposure groups. External validity is limited. Results may also reflect a single institution culture and time period rather than generalizing broadly. Self reports of trust and AI familiarity can introduce measurement bias. People might say they trust something more or less than they actually do when making real decisions.
Findings should therefore be interpreted as most applicable to student email contexts and treated cautiously when generalizing to workplaces or the general public. That said, college students are a reasonable starting point. They're heavy email users, they're encountering AI tools constantly, and they represent the workforce of the near future. Understanding how this demographic responds to AI mediated communication has practical value even if it doesn't immediately generalize to everyone.
The broader methodological challenge is ecological validity. Lab settings differ from real email contexts. Participants know they're in a study. They're evaluating emails from hypothetical senders rather than actual colleagues or supervisors they have relationships with. Single exposures differ from repeated interactions where trust would develop over time. These are real constraints, but they're unavoidable in experimental research that needs tight control to isolate causal effects.
Where This Goes Next
This research is actively ongoing at UTRGV's MARS Lab as part of my Master's in Computer Science. We're continuously refining the protocol, expanding the scenarios, and working toward launching the full study. Beyond the immediate study, there are so many directions this could go. Different communication channels like chat or social media. Cross cultural trust differences. Longitudinal trust development as people gain experience with AI mediated communication. Real world field studies in actual organizations.
The research outcomes will inform AI communication tool design, organizational AI adoption strategies, email transparency standards, and trust building interventions. If HITL proves effective, I can see it becoming standard practice. Tools could be designed to make human oversight explicit and easy. Organizations could adopt policies requiring human review before AI generated messages are sent. Disclosure could become routine and accepted rather than a credibility killer.
But first, I need to actually run the study and see what the data say. Theory is great. Predictions are fun. But empirical reality has a way of surprising you. Maybe HITL works exactly as predicted and restores trust beautifully. Maybe it works but only for certain people or certain contexts. Maybe it doesn't work at all and we need to go back to the drawing board. That's the nature of research. You don't know until you test it.
If there's one thing I've learned from building the HCISD AI application and from my swarm robotics work, it's that human AI collaboration is complicated. It's not enough to build something technically impressive. You have to understand how people respond to it, what they trust, what makes them uncomfortable, what helps them feel confident. This trust study is my attempt to understand those human factors in the specific domain of email communication. And honestly, I think it's some of the most important work we can do in AI right now. Because if we can't figure out how to use AI transparently and maintain trust, we're going to end up in a world where everyone uses AI deceptively and nobody knows what to believe.
Connect
Interested in human-AI interaction or trust research?
- School Email: andres.gonzales01@utrgv.edu
- Personal Email: andrisgonzalis@gmail.com
- GitHub: @andres-ai-dev
I'm always happy to talk about trust, transparency, and how we can build AI systems that people actually want to use.